커넥션을 맺는다는 것: DB 커넥션과 애플리케이션 커넥션은 다른가요?
프롤로그: 하나의 질문에서 시작하겠습니다
“DB 커넥션이랑 애플리케이션 커넥션은 다른 건가요?”
이 질문을 받으면, 대부분의 개발자 머릿속에는 비슷한 키워드가 떠오릅니다.
JDBC, HikariCP, 트랜잭션, DataSource.getConnection()…
그런데 잠깐. 한 발 더 들어가 봅시다.
“커넥션을 맺는다는 건, 도대체 어떤 행위를 하는 건가요?”
개발자는 DataSource.getConnection()을 떠올리고, OS 커널은 socket(AF_INET, ...)을 실행합니다. 같은 “커넥션”이라는 단어지만, 바라보는 세계가 완전히 다릅니다.
이 글은 바로 이 질문에서 출발합니다.
DB도, 스프링도, 잠시 잊어주세요. 우리가 먼저 이해해야 할 것은 운영체제의 세계입니다.
커넥션이라는 단어는 DB만의 것이 아닙니다. OS가 먼저 만들고, 프로토콜이 의미를 부여하고, 애플리케이션이 빌려 쓰는 것입니다.
1. “커넥션을 맺는다”는 것
1.1 운영체제는 커넥션을 이렇게 봅니다
“커넥션”이라는 단어를 들으면, 두 컴퓨터가 서로 연결된 모습을 떠올리기 쉽습니다.
틀린 말은 아닙니다. 하지만 운영체제에게 “커넥션을 맺는다”는 행위는 굉장히 구체적입니다.
커널이 소켓(socket)이라는 자료구조를 하나 만들고, 상대방의 소켓과 양방향으로 바이트를 주고받을 수 있는 상태로 세팅하는 것.
이게 전부입니다.
여기서 주목해야 할 단어는 “상태”입니다.
커넥션은 눈에 보이는 전선이 아닙니다. 커널 메모리 안에 존재하는 상태값입니다. 양쪽 호스트의 커널이 각각 “나는 저쪽과 연결되어 있다”는 상태를 기억하고 있을 때, 우리는 그것을 “커넥션이 맺어졌다”고 부릅니다.
커넥션의 정체는 커널 메모리에 기록된 구조체입니다. 출발지 IP, 목적지 IP, 출발지 포트, 목적지 포트, 그리고 state: ESTABLISHED. 이 다섯 가지가 커넥션의 전부입니다.
// C 의사코드
int fd = socket(AF_INET, SOCK_STREAM, 0); // 소켓 생성
connect(fd, &server_addr, sizeof(server_addr)); // 연결 시도 → 상태가 ESTABLISHED로 바뀜
connect()가 성공하는 순간, 커널은 이 소켓의 상태를 ESTABLISHED로 바꿉니다.
디스크에 파일을 쓰는 게 아닙니다. 물리적으로 뭔가를 꽂는 것도 아닙니다. 그저 메모리에 상태를 기록하는 것, 그것이 “커넥션을 맺는다”의 실체입니다.
1.2 그럼 커넥션 없이는 통신을 못 하나요?
“커넥션을 맺어야만 핸드셰이크도 하고, 통신이 가능해지는 건가요?”
이 질문은 순서를 거꾸로 이해하고 있을 때 나옵니다.
정확히 말하면 이렇습니다:
핸드셰이크를 해야 커넥션이 만들어지는 것이지, 커넥션이 먼저 있고 그 다음에 핸드셰이크를 하는 게 아닙니다.
커넥션이 있어서 핸드셰이크를 하는 게 아닙니다. SYN → SYN-ACK → ACK, 이 세 패킷의 교환이 성공해야 비로소 양쪽 커널에 ESTABLISHED라는 상태가 생깁니다. 그게 커넥션입니다.
TCP의 3-Way Handshake(SYN → SYN-ACK → ACK)는
커넥션을 “맺는 과정” 그 자체입니다.
이 세 패킷의 교환이 끝나면, 양쪽 커널이 각각 소켓 상태를 ESTABLISHED로 바꿉니다.
이 시점에서 비로소 커넥션이라는 것이 존재하게 됩니다.
그리고 하나 더 — TCP 없이도 통신 자체는 됩니다. UDP는 커넥션을 맺지 않고 그냥 패킷을 쏩니다. 상대가 받았는지, 순서가 맞는지는 보장 안 하지만 통신은 합니다. DNS 질의가 대표적이죠.
결국 커넥션은 “신뢰할 수 있는 양방향 통신”을 위한 약속이지, 통신의 전제조건이 아닌 겁니다.
💡 정리하면: 커넥션이란, 양쪽 OS가 “우리는 지금 연결되어 있다”고 합의한 약속입니다. 물리적 전선이 아니라, 커널 메모리에 적힌 상태값입니다.
2. 물리적 연결과 논리적 연결
2.1 종이컵 전화기 vs 유선전화
물리적 연결과 논리적 연결의 차이. 이걸 이해하는 가장 쉬운 방법은, 아주 오래된 장난감을 떠올리는 겁니다.
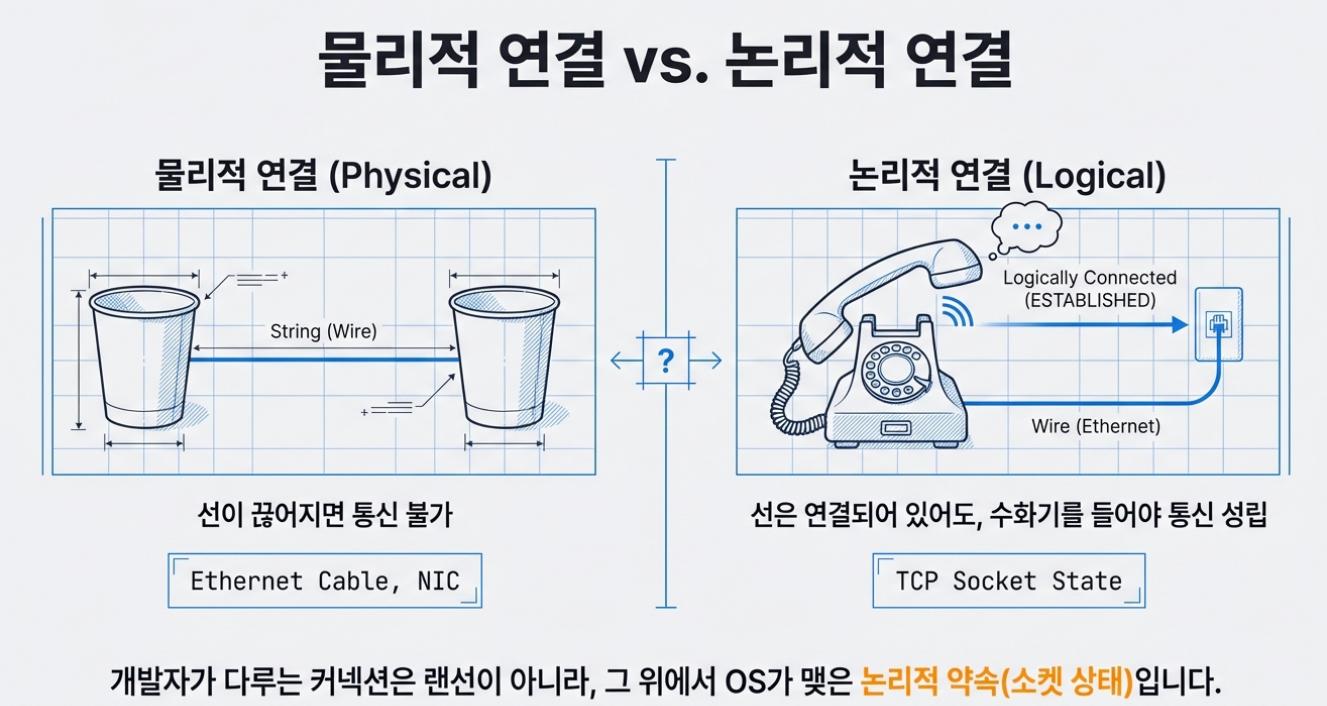
왼쪽이 물리적 연결입니다. 선이 끊어지면 끝. 오른쪽이 논리적 연결입니다. 선은 항상 꽂혀 있지만, 수화기를 들어야 “통화”가 성립합니다.
종이컵 전화기를 떠올려 보세요.
종이컵 두 개를 실로 연결합니다. 실이 팽팽해야 소리가 전달되고, 실이 끊어지면 통신도 끊어집니다.
이게 물리적 연결입니다. 매개체가 눈에 보이고, 손으로 만질 수 있고, 끊어지면 물리적으로 다시 이어야 합니다.
이번엔 유선전화를 생각해 보세요.
벽에 전화선을 꽂으면, 전화국 교환기를 거쳐 상대방과 연결됩니다. 그런데 전화를 끊어도 전화선은 벽에 꽂혀 있잖아요?
물리적 선은 항상 연결되어 있습니다. 하지만 “통화”라는 논리적 연결은, 수화기를 들고 번호를 눌러야 시작되고, 수화기를 내리면 끝납니다.
2.2 네트워크에서도 똑같습니다
이 비유를 네트워크로 옮기면 이렇습니다.
| 구분 | 물리적 연결 | 논리적 연결 |
|---|---|---|
| 비유 | 종이컵 + 실 | 유선전화의 “통화” |
| 네트워크에서 | 이더넷 케이블, 광섬유, NIC | TCP 소켓 (커널 메모리의 상태) |
| 끊어지면? | 랜선을 물리적으로 다시 꽂아야 함 | 커널이 상태를 다시 만들면 됨 |
| 존재 조건 | 물질이 연결되어 있어야 함 | 양쪽 OS가 합의만 하면 됨 |
개발자가 코드에서 다루는 커넥션은 전부 논리적 연결입니다.
getConnection()이 반환하는 건 랜선이 아닙니다.
커널의 소켓 상태 위에 DB 프로토콜이 한 겹 더 올라간, 논리적 구조물입니다.
물리적 연결(케이블, NIC, 스위치)은 이미 인프라 차원에서 다 깔려 있고, 그 위에서 논리적 연결을 맺었다 끊었다 하는 것. 그게 우리가 매일 쓰는 “커넥션”입니다.
💡 물리적 연결 = 케이블이 꽂혀 있는 상태. 논리적 연결 = 그 케이블 위에서 OS가 만든 소켓 상태. 개발자가 다루는 모든 커넥션은 논리적 연결입니다.
3. 그렇다면 DB 커넥션이란 뭔가요?
3.1 논리적 연결 위에 쌓이는 또 하나의 논리적 연결
여기서 한 단계 더 들어갑니다.
TCP 커넥션이 맺어졌다고 해서, DB 커넥션이 자동으로 생기는 게 아닙니다.
TCP 커넥션은 그저 “양쪽 커널이 바이트를 주고받을 준비가 됐다”는 상태일 뿐입니다.
이 파이프 위로 MySQL 패킷이 흐를 수도 있고, HTTP 요청이 흐를 수도 있고, 우리가 만든 자체 프로토콜이 흐를 수도 있습니다. 커널은 관심이 없습니다.
DB 커넥션이 되려면, TCP 커넥션이 수립된 이후에 DB만의 프로토콜 핸드셰이크가 한 번 더 필요합니다.
MySQL을 예로 들면 이런 과정을 거칩니다:
- 서버가 먼저 자기 버전과 인증 정보를 담은 패킷을 보내고
- 클라이언트가 사용자 이름과 비밀번호로 응답하고
- 서버가 인증을 확인한 뒤 OK를 보냅니다
여기까지 끝나야 비로소 DB 세션이 탄생합니다.
즉, 커넥션에는 계층이 있습니다.
우리가 “DB 커넥션”이라고 부르는 건, 사실 네 겹의 합작품입니다. 맨 아래 물리 계층은 항상 연결되어 있고(Always connected), 그 위에 커널의 TCP 소켓, DB의 인증 세션, 그리고 Java 드라이버의 래퍼 객체가 차곡차곡 쌓여 있습니다.
| 계층 | 누가 만드는가 | 무엇이 생기는가 |
|---|---|---|
| L1~L2 | 케이블, NIC, 스위치 | 물리적 연결 — 전기 신호가 오갈 수 있는 상태 |
| L4 | OS 커널 (TCP 스택) | TCP 커넥션 — 소켓 상태 (1차 논리적 연결) |
| L7 | DB 서버 프로세스 | DB 세션 — 인증 완료 + 상태 컨테이너 (2차 논리적 연결) |
| App | JDBC 드라이버 / 커넥션 풀 | Connection 객체 — 위 모든 것을 감싼 래퍼 |
개발자가 “DB 커넥션”이라고 부르는 것은 이 네 계층이 한 번에 수립된 결과물입니다.
하나처럼 보이지만, 실제로는 네 겹의 합작품이죠.
3.2 DB 세션은 가볍지 않습니다
TCP 소켓 위에 DB 세션이 올라가면, 이 세션은 곧바로 상태를 짊어지기 시작합니다.
트랜잭션 격리 수준, SET으로 바꾼 세션 변수, 임시 테이블,
Prepared Statement 캐시, 진행 중인 트랜잭션의 락 정보까지.
이 모든 상태가 세션이 끊어지는 순간 전부 사라집니다.
그래서 DB 커넥션을 새로 만드는 건, 단순히 TCP 소켓을 하나 여는 것보다 훨씬 비쌉니다.
커넥션 하나를 새로 만드는 데 드는 비용 청구서입니다. TCP Handshake 0.5ms, TLS Handshake 2.0ms, DB 인증 및 세션 초기화 5.0ms. 합계 약 8ms. 반면 단순한 SELECT 쿼리는 약 0.1ms. 배보다 배꼽이 80배 큽니다.
💡 커넥션 수립 비용: TCP Handshake (~0.5ms) + TLS Handshake (~2.0ms) + DB 인증·세션 초기화 (~5.0ms) = 동일 데이터센터 안에서도 약 8ms. 단순한
SELECT쿼리(~0.1ms)보다 수십 배 비쌉니다.
4. 커넥션 풀이 진짜로 들고 있는 것
4.1 이 글의 핵심 질문
자, 이제 핵심으로 들어갑시다.
“스프링에서 DB 커넥션 풀을 만들잖아요. 트랜잭션을 안 쓰는 중에도 유휴 커넥션들이 있는데, 이 커넥션들은 물리적으로 연결되어 있는 건가요?”
이 질문에 답하려면, 앞에서 정리한 계층 구분이 반드시 필요합니다.
4.2 유휴 커넥션은 “논리적으로” 연결되어 있습니다
세 가지 관점에서 각각 살펴보겠습니다.
① 물리적 연결 (케이블, NIC)
커넥션 풀과 무관하게 항상 연결되어 있습니다. 서버가 데이터센터에 있고 랜선이 꽂혀 있으면, 애플리케이션이 켜져 있든 꺼져 있든 물리적 연결은 그대로입니다. 이 레이어는 커넥션 풀의 관심사가 아닙니다.
② TCP 소켓
유휴 커넥션은 실제로 ESTABLISHED 상태의 TCP 소켓을 유지하고 있습니다.
커널 메모리에 소켓 구조체가 존재하고,
파일 디스크립터도 할당되어 있고,
상대편 DB 서버 커널에도 대응하는 소켓이 살아 있습니다.
데이터가 오가지 않을 뿐, 양쪽 커널 모두 “이 연결은 살아있다”고 기억하고 있습니다.
③ DB 세션
DB 서버 쪽에도 해당 커넥션에 대응하는 세션(또는 스레드, 프로세스)이 있습니다.
MySQL이라면 SHOW PROCESSLIST에서 Sleep 상태,
PostgreSQL이라면 pg_stat_activity에서 idle 상태로 보입니다.
놀고 있는 커넥션은 끊긴 게 아닙니다. 아무 말도 안 하고 있지만, 수화기는 들고 있는 상태입니다. 커널 메모리의 소켓 버퍼도, DB 서버의 스레드도 계속 자원을 점유 중입니다.
mysql> SHOW PROCESSLIST;
+----+------+-----------+------+---------+------+-------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+-----------+------+---------+------+-------+------------------+
| 42 | app | 10.0.1.5 | mydb | Sleep | 127 | | NULL |
| 43 | app | 10.0.1.5 | mydb | Sleep | 84 | | NULL |
| 44 | app | 10.0.1.5 | mydb | Query | 0 | exec | SELECT * FROM... |
+----+------+-----------+------+---------+------+-------+------------------+
Id 42, 43이 바로 유휴 커넥션입니다.
쿼리를 하나도 실행하지 않고 있지만, TCP 소켓도 살아있고, DB 세션도 살아있습니다. 커널의 소켓 버퍼가 메모리를 먹고, DB 서버의 스레드가 자원을 차지합니다.
놀고 있지만, 비용은 나가고 있는 상태입니다.
💡 유휴 커넥션은 “끊어진 상태”가 아닙니다. TCP 소켓은
ESTABLISHED, DB 세션은idle. 아무 데이터도 안 흐를 뿐, 연결은 살아 있습니다. 유선전화로 치면, 수화기를 든 채 아무 말도 안 하고 있는 상태입니다.
4.3 그러면 왜 이 비용을 감수하면서까지 연결을 유지하나요?
“연결이 안 되어 있다면 커넥션 풀의 존재 이유가 뭔가요?”
사실 이 질문의 전제가 다릅니다.
커넥션 풀은 연결이 안 되어 있는 게 아니라, 연결을 미리 만들어서 유지하고 있는 것입니다.
그리고 그 이유는 단 하나. 커넥션을 새로 만드는 비용이 너무 비싸기 때문입니다.
커넥션 풀은 “연결을 미리 맺어두고, 수화기를 들고 있는 상태를 유지”하는 겁니다. 풀 없이 매번 새로 만들면 요청당 3~8ms. 풀에서 꺼내면 0.003ms. 약 1,000배 차이.
구체적으로 비교해 보겠습니다.
| 방식 | 커넥션 획득 비용 | 초당 1,000건 처리 시 |
|---|---|---|
| 매번 새로 생성 | ~3-8ms | 총 3~8초 소비 (사실상 불가능) |
| 커넥션 풀에서 꺼내기 | ~0.003ms | 총 3ms 소비 (무시 가능) |
매 요청마다 커넥션을 새로 만들면, 순수하게 연결 수립에만 초당 수 초가 날아갑니다. 초당 1,000건을 처리하는 서버에서는 산술적으로 불가능한 구조입니다.
커넥션 풀은 이 비용을 딱 한 번만 지불하고, 그 이후로는 이미 만들어진 커넥션을 빌려 쓰고 돌려받는 방식입니다.
유휴 커넥션이 TCP 소켓과 DB 세션을 잡아먹는 건 맞지만, 매번 새로 만드는 비용에 비하면 훨씬 싼 장사입니다.
5. 유휴 커넥션이 “살아있다”는 말의 함정
5.1 앱은 살아있다고 믿지만, 진짜 살아있을까?
여기서 실무적으로 정말 중요한 함정이 등장합니다.
커넥션 풀의 유휴 커넥션이 “살아있다”는 건, 애플리케이션이 그렇게 믿고 있다는 뜻이지, 진짜 살아있다는 보장이 아닙니다.
유휴 커넥션이 오래 방치되면 어떤 일이 벌어질까요?
중간 경로에 있는 방화벽, 로드밸런서, NAT 장비가 “이 커넥션, 한참 동안 패킷이 안 왔는데? 죽은 거 아냐?” 하고 자기 세션 테이블에서 일방적으로 삭제해버립니다.
양쪽 호스트에게는 아무 통보도 하지 않습니다.
App과 DB 모두 “우리 연결되어 있어”라고 믿고 있습니다. 하지만 중간의 방화벽이 유휴 시간이 길다며 세션을 조용히 지워버렸습니다. 결과는? 유령 커넥션입니다.
이 상태가 바로 Half-Open Connection입니다.
애플리케이션 쪽 커널: “소켓 상태? ESTABLISHED입니다.”
DB 서버 쪽 커널: “네, 저도 ESTABLISHED요.”
중간 방화벽: “그 연결? 저는 30분 전에 지웠는데요?”
실제로 패킷을 보내는 순간, 비로소 연결이 죽었다는 걸 알게 됩니다.
// 풀에서 꺼낸 커넥션으로 쿼리 실행 시도
// → TCP RST 수신 → "Connection reset by peer"
// → 또는 타임아웃까지 무응답 → "Socket read timed out"
5.2 커넥션 풀은 이걸 어떻게 막을까?
이 문제에 대한 방어 전략은 크게 세 가지입니다.
Validation Query: 쓰기 전에 “야, 살아있어?” 찔러보기. TCP Keepalive: OS가 주기적으로 빈 패킷을 보내서 중간 장비 세션을 갱신. Max Lifetime: 30분 지나면 아무리 멀쩡해도 폐기하고 새로 만들기.
① Validation Query (연결 검증 쿼리)
커넥션을 풀에서 꺼낼 때, SELECT 1 같은 가벼운 쿼리를 먼저 날려봅니다.
응답이 안 오면? 죽은 커넥션이니 폐기하고, 새로 만듭니다.
“쓰기 전에 한 번 찔러보는” 전략입니다.
② TCP Keepalive
OS 커널 레벨에서 주기적으로 빈 패킷을 보냅니다. “야, 거기 있니?” 하고 확인하는 동시에, 중간 장비의 세션 테이블도 갱신시켜줍니다. 이건 애플리케이션이 하는 게 아니라 커널이 알아서 하는 일입니다.
③ Max Lifetime (최대 수명)
커넥션이 아무리 건강해 보여도, 일정 시간이 지나면 강제로 폐기하고 새로 만듭니다. HikariCP 기본값은 30분. “오래된 건 그냥 안 믿겠다”는 보수적인 접근입니다.
# HikariCP 설정 예시
spring.datasource.hikari.connection-test-query=SELECT 1
spring.datasource.hikari.keepalive-time=300000 # 5분마다 생존 확인
spring.datasource.hikari.max-lifetime=1800000 # 30분 지나면 강제 교체
spring.datasource.hikari.minimum-idle=5 # 최소 유휴 커넥션 5개 유지
spring.datasource.hikari.maximum-pool-size=10 # 최대 10개
💡 유휴 커넥션은 “연결되어 있다고 믿는” 상태일 뿐입니다. 진짜 살아있는지는 패킷을 보내봐야 알 수 있습니다. Validation Query와 TCP Keepalive는 이 간극을 메우기 위한 안전장치입니다.
6. 다시 처음 질문으로 돌아가겠습니다
6.1 OS는 DB 커넥션과 HTTP 커넥션을 구분할까요?
“DB 커넥션이랑 애플리케이션 커넥션은 다른 건가요?”
운영체제의 관점에서 답하면, 같습니다. 정확히 말하면, OS는 애초에 그 구분을 하지 않습니다.
커널에게 소켓은 그냥 소켓입니다. 그 위로 MySQL 패킷이 흐르든, HTTP 요청이 흐르든, gRPC 호출이 흐르든, 커널이 하는 일은 완전히 동일합니다.
바이트를 받아서 TCP 세그먼트로 감싸고, IP 패킷으로 한 번 더 감싸고, 이더넷 프레임으로 포장해서 NIC에 넘기는 것. 그게 전부입니다.
ss -tnp 출력에서 DB Connection과 HTTP Connection은 목적지 포트만 다를 뿐입니다. OS 입장에서는 완전히 똑같은 소켓이고, 똑같은 방식으로 관리합니다. 차이를 만드는 건 소켓 위에 올라가는 프로토콜입니다.
$ ss -tnp
ESTAB 10.0.1.5:48234 10.0.1.10:3306 java # DB 커넥션 (MySQL)
ESTAB 10.0.1.5:48240 10.0.1.20:8080 java # HTTP 커넥션
ESTAB 10.0.1.5:48250 10.0.1.30:6379 java # Redis 커넥션
이 세 줄의 차이는 목적지 IP와 포트 번호뿐입니다. 커널이 할당하는 자원, 관리하는 방식, 유지하는 상태는 완전히 동일합니다.
“DB 커넥션”과 “애플리케이션 커넥션”이라는 구분은 커널의 관점이 아니라, L7 프로토콜과 개발자의 관점에서만 의미가 있는 구분입니다.
6.2 그런데 왜 DB 커넥션만 유독 무겁게 느껴질까요?
그건 소켓 위에 올라가는 프로토콜의 성격이 다르기 때문입니다.
HTTP는 가볍습니다. 요청이 끝나면 상태를 털어버립니다(Stateless). 반면 DB 커넥션은 트랜잭션, 세션 변수, 임시 테이블, 락 등 잔뜩 짐을 지고 다닙니다(Stateful). 그래서 HTTP처럼 아무나 돌려쓸 수가 없습니다.
HTTP 커넥션은 가볍습니다. (Stateless)
각 요청은 독립적이고, 커넥션 위에 상태가 거의 없습니다. 그래서 HTTP/2에서는 TCP 커넥션 하나 위에 수백 개의 요청을 동시에 실어 보낼 수 있죠. 요청이 끝나면 상태를 털어버리면 그만입니다.
DB 커넥션은 무겁습니다. (Stateful)
트랜잭션 상태, 세션 변수, 임시 테이블, Prepared Statement 캐시, 락 정보… 이 모든 것이 세션에 묶여 있습니다. 그래서 커넥션을 다른 클라이언트와 돌려 쓰는 게 구조적으로 어렵습니다.
바로 이 Stateful vs Stateless의 차이가, 같은 TCP 소켓인데도 DB 커넥션만 유독 풀링, 수명 관리, 검증 같은 특별한 관리가 필요한 이유입니다.
7. 이걸 알면 실무에서 뭐가 달라지나요?
7.1 커넥션 풀 크기, 감으로 정하지 마세요
왼쪽: 커넥션 풀 크기 공식은 CPU 코어 수 × 2. 커넥션이 많으면 컨텍스트 스위칭 비용 때문에 오히려 느려집니다. 오른쪽: 에러 메시지와 계층의 매핑. 에러를 보면 어디를 봐야 하는지 바로 판단할 수 있습니다.
“커넥션 풀은 크면 클수록 좋다”고 생각하기 쉽습니다.
하지만 유휴 커넥션도 TCP 소켓과 DB 세션을 점유한다는 걸 알면, 이 생각이 왜 위험한지 보입니다.
PostgreSQL은 커넥션 하나가 프로세스 하나입니다. 커넥션 100개면 프로세스가 100개 떠 있습니다. 유휴 상태라도 프로세스당 5~10MB 메모리를 먹습니다.
MySQL은 커넥션 하나가 스레드 하나인데, 스레드가 수천 개 되면 컨텍스트 스위칭 비용이 실제 쿼리 처리 시간을 초과해버릴 수 있습니다.
💡 적정 풀 크기 ≈ CPU 코어 수 × 2. 직관에 반하지만, 작은 풀이 큰 풀보다 처리량이 높은 경우가 많습니다. 커넥션이 늘면 락 경합, 메모리 압박, 컨텍스트 스위칭이 동시에 증가하기 때문입니다.
7.2 “커넥션 에러”가 뜨면, 먼저 계층을 파악하세요
커넥션의 계층을 이해하면, 장애 분석의 출발점 자체가 달라집니다.
같은 “커넥션 에러”라도 어느 계층의 문제인지에 따라 봐야 할 곳과 해법이 완전히 다릅니다.
| 에러 메시지 | 문제 계층 | 봐야 할 것 |
|---|---|---|
Connection timed out |
L4 (TCP/네트워크) | tcpdump, 방화벽 규칙, 네트워크 경로 |
Access denied, Too many connections |
L7 (DB 프로토콜) | DB 로그, max_connections, 인증 설정 |
Connection pool exhausted |
App (커넥션 풀) | 풀 사이즈, 커넥션 반환 누락, 스레드 덤프 |
CLOSE_WAIT 누적 |
L4 ↔ App 사이 | close() 미호출, 커넥션 누수 |
7.3 CLOSE_WAIT — 계층이 어긋날 때 벌어지는 일
계층 분리를 체화하면 이해할 수 있는 대표적인 현상이 CLOSE_WAIT입니다.
DB 서버가 커넥션을 끊었습니다 (FIN 패킷을 보냈습니다).
하지만 애플리케이션 쪽에서 close()를 호출하지 않으면,
소켓이 CLOSE_WAIT 상태에 영원히 머물게 됩니다.
커널은 “애플리케이션이 close() 호출하겠지” 하고 기다리고,
애플리케이션은 커넥션 객체를 참조만 하고 안 쓰고 있고,
이 소켓은 타임아웃으로 자동 정리가 되지 않습니다.
파일 디스크립터를 영구히 점유합니다.
이게 쌓이면?
Too many open files로 서버 전체가 멈춥니다.
CLOSE_WAIT은 커널(L4)이 보내는 신호를 애플리케이션(L7)이 무시할 때 발생합니다.
물리적 연결과 논리적 연결의 계층이 다르기 때문에 생기는 현상이고,
이 구분을 모르면 원인을 진단할 수 없습니다.
결론: 추상화 아래를 보는 개발자
처음의 질문으로 돌아갑시다.
“DB 커넥션이랑 애플리케이션 커넥션은 다른 건가요?”
OS에게는 같습니다. 둘 다 TCP 소켓이고, 파일 디스크립터이고, 커널 메모리의 상태입니다. 그 위에 어떤 프로토콜이 올라가느냐에 따라 DB 커넥션이 되기도 하고, HTTP 커넥션이 되기도 할 뿐입니다.
정리하겠습니다.
커넥션은 전선이 아닙니다. 메모리의 상태입니다.
풀(Pool)은 캐시입니다. 비싼 논리적 연결의 생성 비용을 아끼기 위한 것입니다.
계층을 보십시오. L4와 L7을 구분하면 장애의 원인이 보입니다.
커넥션 풀의 유휴 커넥션은 물리적으로 연결되어 있느냐고요?
물리적 연결(케이블)은 커넥션 풀과 무관하게 항상 존재합니다. 논리적 연결(TCP 소켓 + DB 세션)은 유휴 상태에서도 유지되며 자원을 소비합니다.
커넥션 풀이 이 비용을 감수하는 이유는, 논리적 연결을 새로 만드는 비용이 너무 비싸서, 한 번 만들어놓고 재사용하는 게 압도적으로 이득이기 때문입니다.
도구(Library)의 사용법을 넘어, 그 도구가 딛고 있는 땅(OS/Network)을 이해하십시오.